
Executive Summary
- The AI transformation relies on usage of AI models that implement complex algorithmic tasks.
- Repositories such as Hugging Face are home to millions of pretrained models. Anyone can upload any model, and anyone can download.
- Using untrusted third-party models introduces a supply chain risk of code execution, either in model load time or in inference time.
- To mitigate those risks, Hugging Face and some vendors offer the ability to scan models for malicious payloads.
- Unfortunately, the current scanning method (which we call static scanning) is susceptible to numerous bypasses due to several inherent shortcomings, which cannot be properly dealt with without damaging the scanners’ accuracy.
- To overcome those shortcomings, Aim Labs has devised a novel, patent-pending model scanning method which addresses the flaws of the current scanners approach.
- We recently presented this approach in Black Hat USA 2025, in our talk “Smashing Model Scanners: Advanced Bypass Methods and a Novel Detection Approach”.
TL;DR
Current model scanners rely on a preset denylist of functions and modules. This list aims to extensively capture callables attackers use to embed malicious payloads into model files, to achieve a full supply chain attack. Unfortunately, scanners cannot hope to create a comprehensive denylist as doing so requires going over millions of Python functions and understanding the possible bad flows of each one. Aside from that, we note that models often rely on code, bytecode, or just on dynamically-determined values, embedded into the model file or model repository. This makes static analysis of the model file simply unfeasible from a computational standpoint, as static code analysis is an NP-hard problem.
To meet these challenges, Aim Labs has developed a novel, patent-pending dynamic approach which relies on executing the models in a sandbox environment. Tracing the model operations in this environment, we are able to provide much better visibility into the actual risks embedded into a given model and overcome the inherent shortcomings static scanners present.
How do current model scanners work?
Models come in various formats, depending on the ML framework that was used to train and save them. While many frameworks introduce their own format, some (such as MLflow) simply pickle the model object and unpickle (the process of deserializing a pickle blob) it upon loading.
An example of a dedicated format used by a popular framework can be found in the Keras v3 format used by the Tensorflow library. Keras v3 saved the model architecture in a json format such as:
{"module": "keras", "class_name": "Sequential", "config": {"name": "sequential_5", "trainable": true, "dtype": {"module": "keras", "class_name": "DTypePolicy", "config": {"name": "float32"}, "registered_name": null, "shared_object_id": 13951589296}, "layers": [{"module": "keras.layers", "class_name": "InputLayer", "config": {"batch_shape": [null, 10], "dtype": "float32", "sparse": false, "name": "input_layer_5"}, "registered_name": null}, {"module": "keras.layers", "class_name": "Dense", "config": {"name": "dense_5", "trainable": true, "dtype": {"module": "keras", "class_name": "DTypePolicy", "config": {"name": "float32"}, "registered_name": null}, "units": 1, "activation": "linear", "use_bias": true, "kernel_initializer": {"module": "keras.initializers", "class_name": "GlorotUniform", "config": {"seed": null}, "registered_name": null}, "bias_initializer": {"module": "keras.initializers", "class_name": "Zeros", "config": {}, "registered_name": null}, "kernel_regularizer": null, "bias_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "registered_name": null, "build_config": {"input_shape": [null, 10]}}], "build_input_shape": [null, 10]}, "registered_name": null, "build_config": {"input_shape": [null, 10]}}While JSON is of course considered a safe serialization format, it’s important to note that the process of loading the model from its JSON configuration does not include JSON decoding only. Instead, this JSON configuration is used to recreate modules used as part of the model and are identified by the “class_name” key.
Other formats have similar notions. Pickle model files include functions and modules that need to be called in order to recreate the original model architecture.
With that in mind, current protections from model supply chain attacks, are based on denylisting the functions or modules that are embedded into the model file. As current generation scanners simply read the model file bytes and statically analyse them without executing the model, we dub such scanners as static scanners.
As a concrete example, let’s look at the following code used to generate a malicious model that calls the os.system function to run CLI commands in load time:
import torch
import os
class Malicious:
def __reduce__(self):
return (os.system, ('echo HACKED > /tmp/hacked.txt', ))
torch.save(Malicious(), 'malicious.pt')
As torch format, in essence, is a pickle file saved within a zip file, we can open that zip and inspect the bytes that compose the resulting pickle file:
0: \x80 PROTO 2
2: c GLOBAL 'posix system'
16: q BINPUT 0
18: X BINUNICODE 'echo HACKED > /tmp/hacked.txt'
52: q BINPUT 1
54: \x85 TUPLE1
55: q BINPUT 2
57: R REDUCE
58: q BINPUT 3
60: . STOP
The GLOBAL ‘posix system’ opcode tells the unpickler that this module uses the posix.system function (the same as os.system on posix machines), so it needs to be imported. As static scanners know in advance that this function can be used to run arbitrary CLI commands, they mark any model that has this “GLOBAL” pickle opcode with posix.system as an argument, as unsafe, as this function is included in their denylist.
Static Scanners Are Inherently Flawed
In an effort to develop model scanners that offer true protection, Aim Labs set out on a course to reveal the shortcomings of the current approach. Unfortunately, these margins are too narrow to include all bypass methods, but here are a few selected methods we encountered along the way:
Bypass Method #1 - Overwhelming the Scanner’s Denylist
As static scanners rely at their core on the denylist configuration, we start with the observation that it is impossible for static scanners to have an exhaustive list of unsafe functions. Even if only considering pickle-based formats, there are just too many functions out there that attackers can choose to use. Thousands of python packages, thousands of functions within each one, a dynamic scanner will need to go through millions of functions, deeply analyze each and every one of them, to come to an accurate conclusion whether some of the flows within these functions are unsafe. This is just impossible practically speaking.
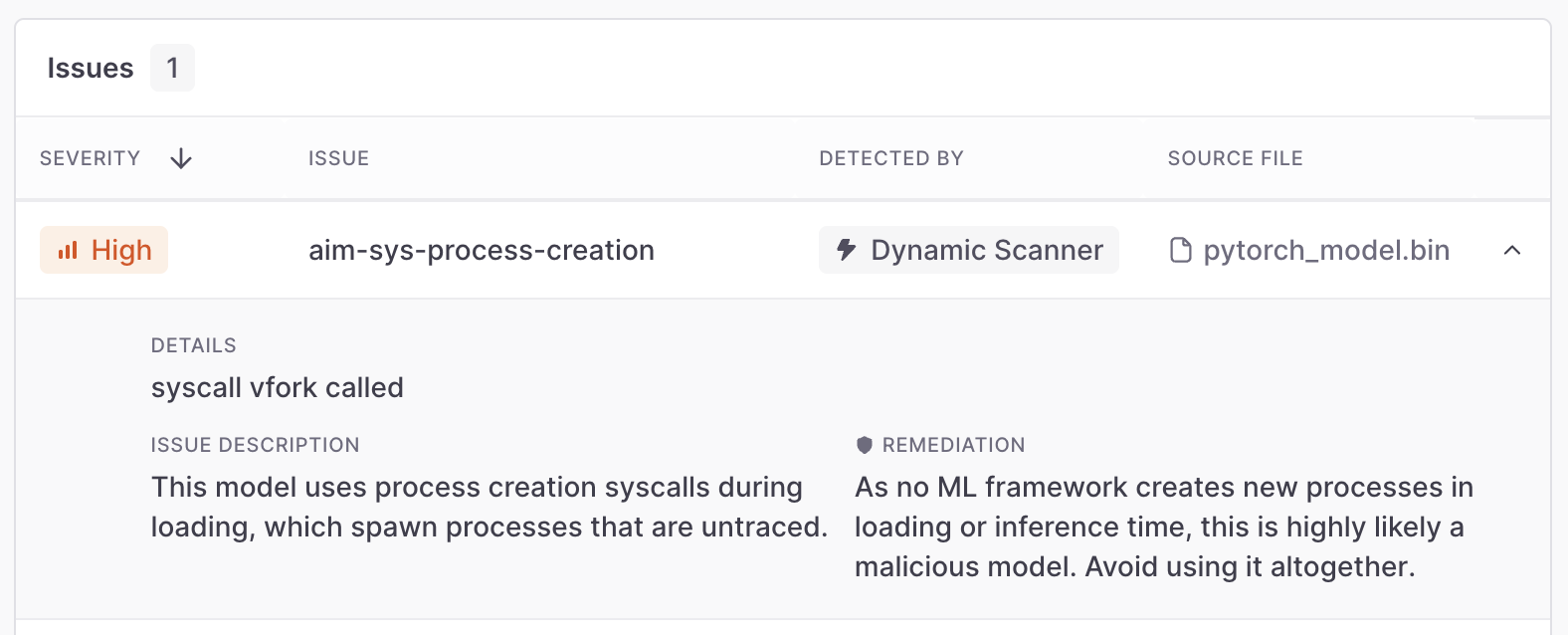
To prove the point, we wrote an AI agent that looks for such functions that static scanners might miss. We instructed the agent to search relatively common GitHub repositories such as numpy and pytorch, for functions that are wrappers around known unsafe python functions (such as subprocess.Popen or exec). By doing so we were able to quickly find dozens of examples that static scanners do not include in their denylist. One of the examples the agent found was the following python function taken from the mlflow.projects.backend.local module:
def _run_entry_point(command, work_dir, experiment_id, run_id):
env = os.environ.copy()
env.update(get_run_env_vars(run_id, experiment_id))
env.update(get_databricks_env_vars(tracking_uri=mlflow.get_tracking_uri()))
if not is_windows():
process = subprocess.Popen(
["bash", "-c", command], close_fds=True, cwd=work_dir, env=env
)
else:
process = subprocess.Popen(
["cmd", "/c", command], close_fds=True, cwd=work_dir, env=env
)
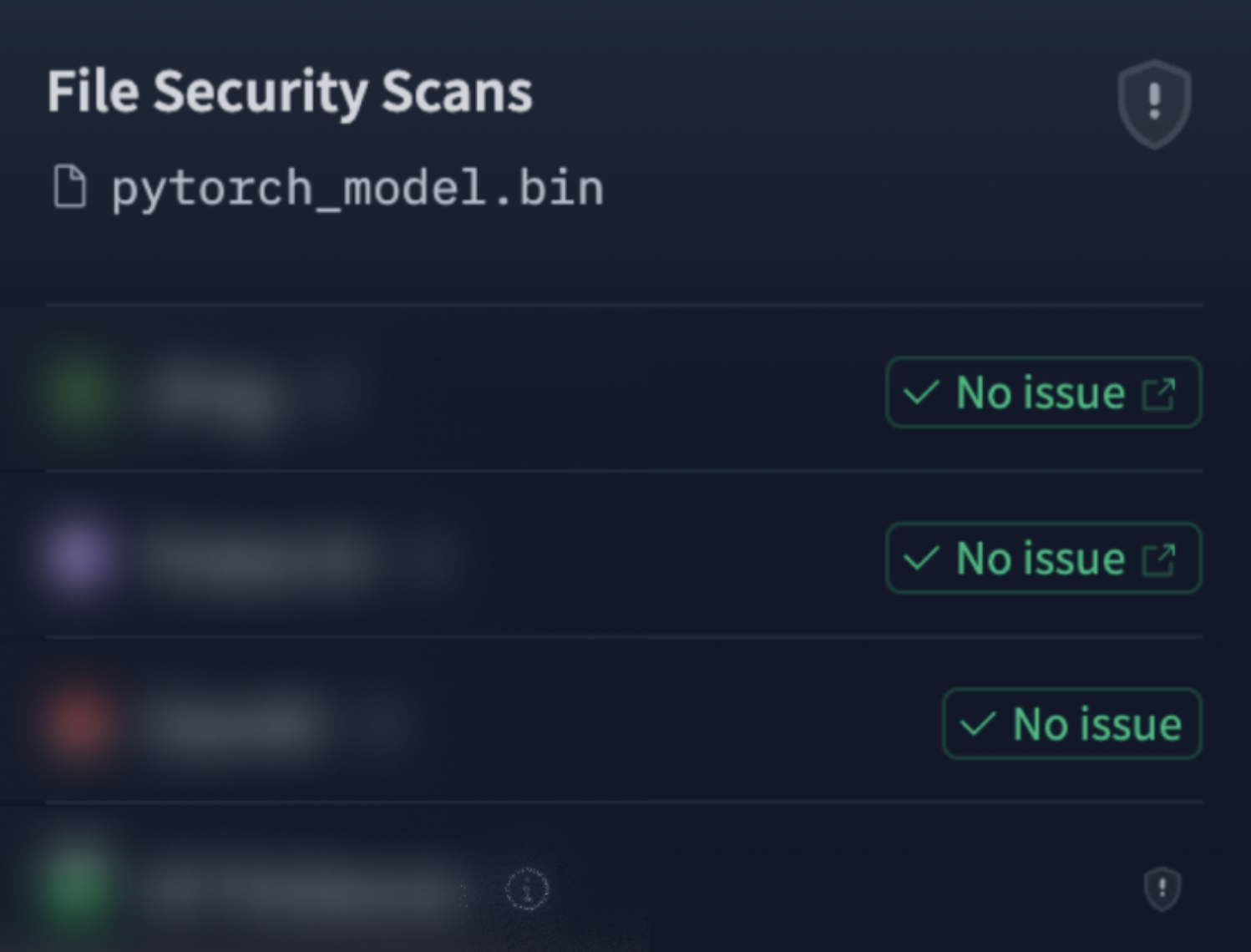
return LocalSubmittedRun(run_id, process)As we can see, this function is a simple wrapper around subprocess.Popen. Attackers can utilize this (and similar) functions to run CLI commands on the local machine. Seeing, however, that the function is embedded deep into the MLflow package, it may not come as a surprise that no current scanner included it in its denylist. Thus, an attacker can embed CLI commands into the model file and have it go untraced:
Bypass Method #2 - Utilizing Static Code Analysis Complexity
To showcase another flaw in static scanners, let’s discuss python (byte)code. Essentially, when saving a model with pytorch, the user chooses the pickle_module to use for the pickling process. Choosing pickle_module=dill, for example, allows the user to serialize custom functions into the model file, instead of relying on functions imported using the GLOBAL opcode we saw earlier. Worth highlighting at this point, that there are legitimate uses to this feature, as it allows embedding the entire model into a single model file, even when the model has a custom architecture. Attackers, however, are always one step ahead and utilize all such esoteric features to their advantage. In this instance, attackers can simply embed malicious code into a serialized function, thus evading static scanners that solely inspect GLOBAL pickle opcodes. But even if static scanners evolved and started inspecting the contents of serialized functions, they could not stand a chance. Static code analysis is an NP-hard problem as it is a generalization of the halting problem. Therefore, scanners cannot hope to accurately statically analyze the contents of those functions and figure out what those functions are up to. To showcase this point, we wrote the following function and embedded it into a model file:
def goo(arg):
x = '__im'
y = 'po'
z = 'rt__'
o = 'o'
s = 's'
module = torch.__builtins__[x + y + z](o + s)
module.system("echo \"You've been pwned.\"")
return arg
Simply by breaking up several suspicious strings into different variables, we create a hard-to-analyze function, which essentially ends up running untrusted CLI commands.
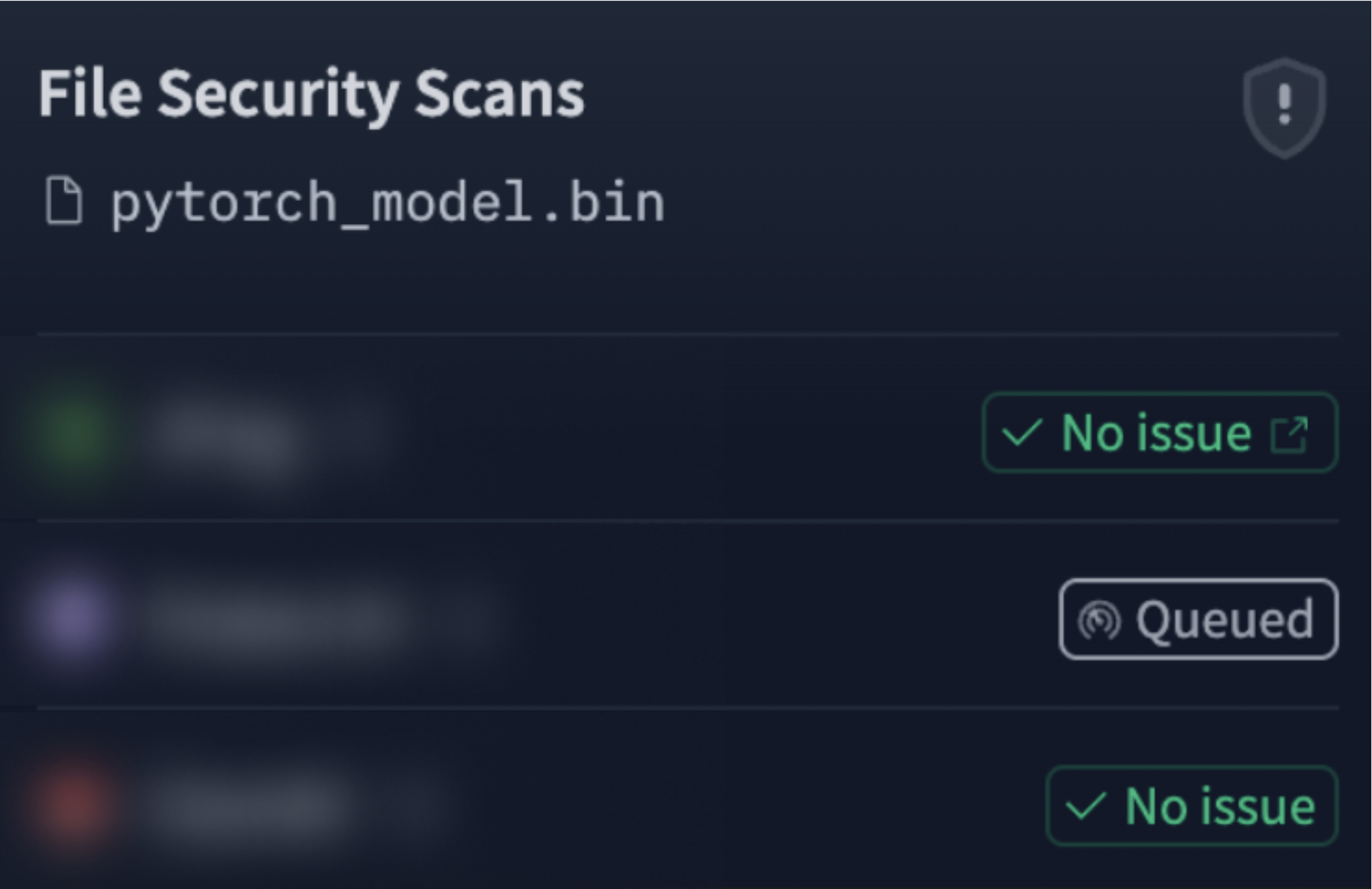
Not surprisingly, given the non-polynomial nature of static code analysis, this custom function was not detected by any of the static scanners HuggingFace suggests (with one scanner not returning any result for weeks):
Bypass Method #3 - Relying on the Scanner’s Over-Simplicity
Another dimension to static scanners being insufficient in accurately assessing the risk associated with model files, is the fact that they are over-simplistic in their emulation of the model operations. To better understand this, let’s dive deeper into how pickle works.
Pickle serialization, unlike common belief, is actually a full-fledged assembly language. It has over 60 opcodes, most of which accept arguments. To save readers the time and tediousness of describing all 60+ opcodes, let’s focus on a few that serve our educational purposes:
- PUSH_STACK / POP_STACK: Push some basic type (string, int, …) onto the top of the pickle stack, which is a LIFO data structure.
- PUT_MEM / GET_MEM: PUTs the value on top of the stack onto the specified (random-access) memory cell, or GETs the value from that cell and pushes it onto the top of the stack.
- PYTHON_IMPORT: Pops the top 2 strings off the stack and pushes the function or module specified by concatenating those strings to one another. For example, if the top of the stack is “system” and the next value on stack is “os”, calling PYTHON_IMPORT will push the os.system function onto the top of the stack.
- CALL_IMPORTED_FUNC: Pops the tuple (let’s call it args) off the top of the stack, and then pops the imported function (func) off the top of the stack, and pushes func(*args) onto the stack.
- INSTANTIATE: Pops 2 strings and a tuple off the top of the stack, and pushes the instantiated class specified by the 2 strings with the tuple as arguments to the instantiation.
With that in mind, let’s examine the following pseudo code which is loyal to HF picklescan’s logic:
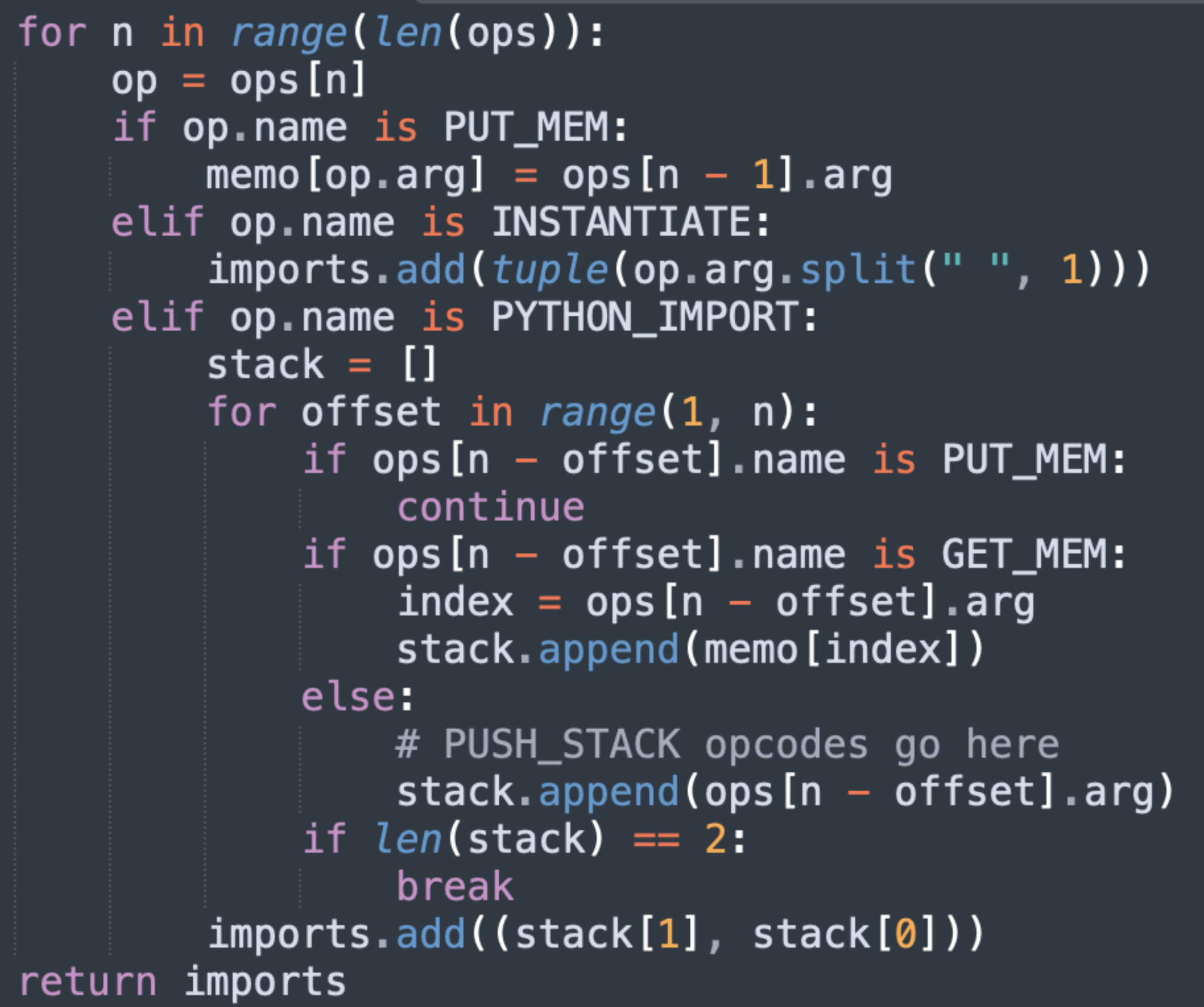
As we can see here, even for our reduced set of opcodes, picklescan does not implement the emulation of all opcodes. Instead, as it is only interested in following imported functions, it tries to recreate the strings used by PYTHON_IMPORT by scanning the opcodes backwards once it encounters this opcode.
The problem is that without fully emulating all opcodes, the scanner risks over-simplification, which is indeed the case here. Its handling of the PUT_MEM opcode assumes what’s put into memory (the top of the stack) is the argument of the previous opcode. While in most cases this is indeed the case, attackers can take advantage of this slight over-simplification to completely fool the scanner. Here is an example payload an attacker might inject and the deviation it creates in the scanner’s state from the true unpickling state:
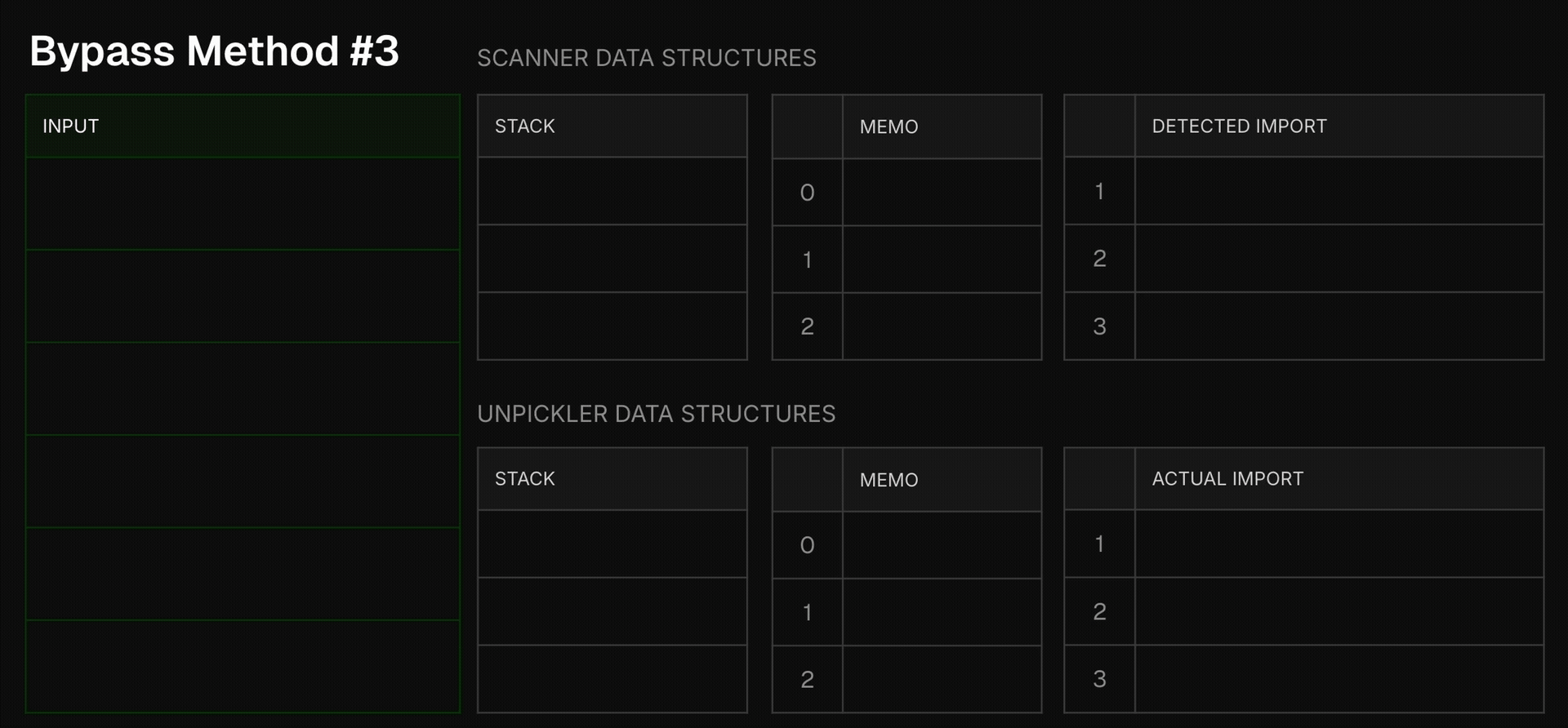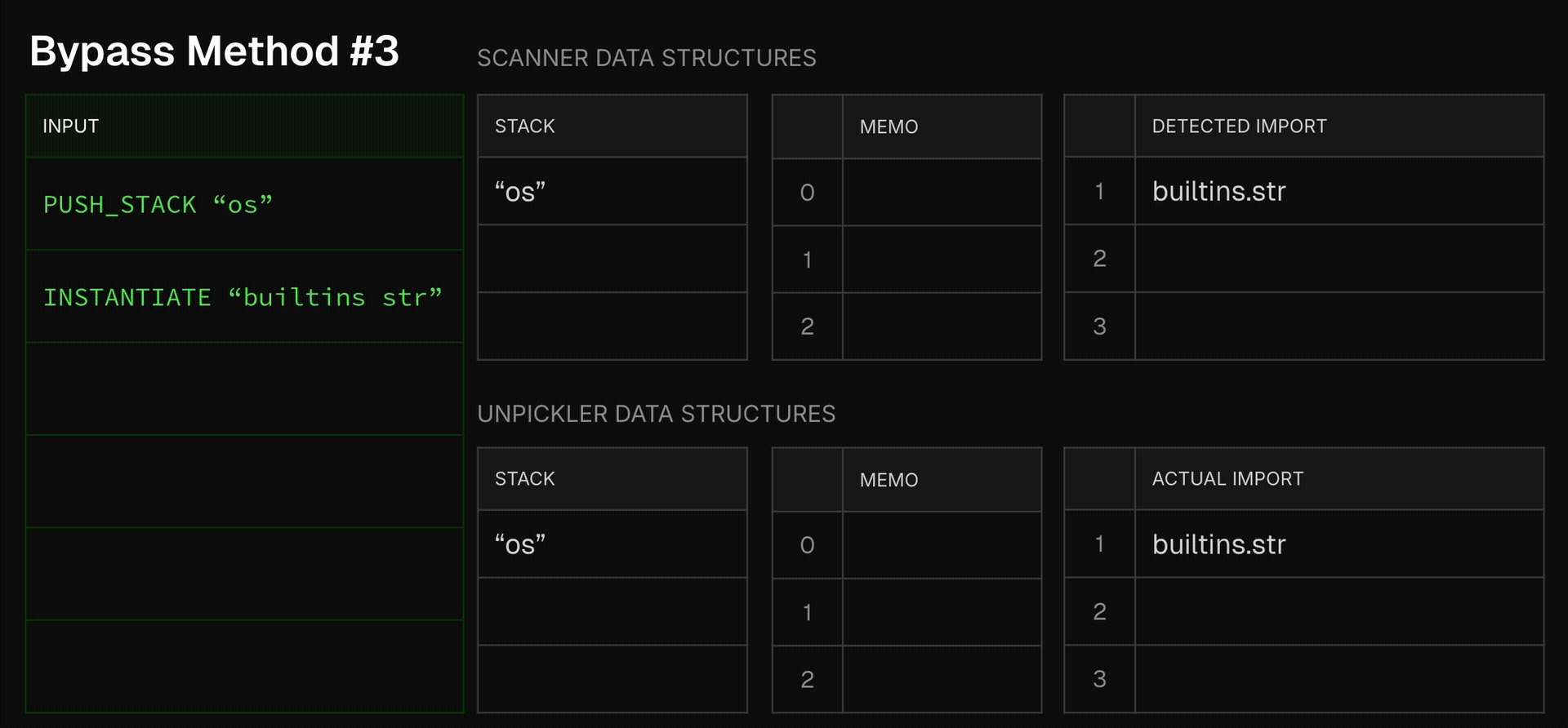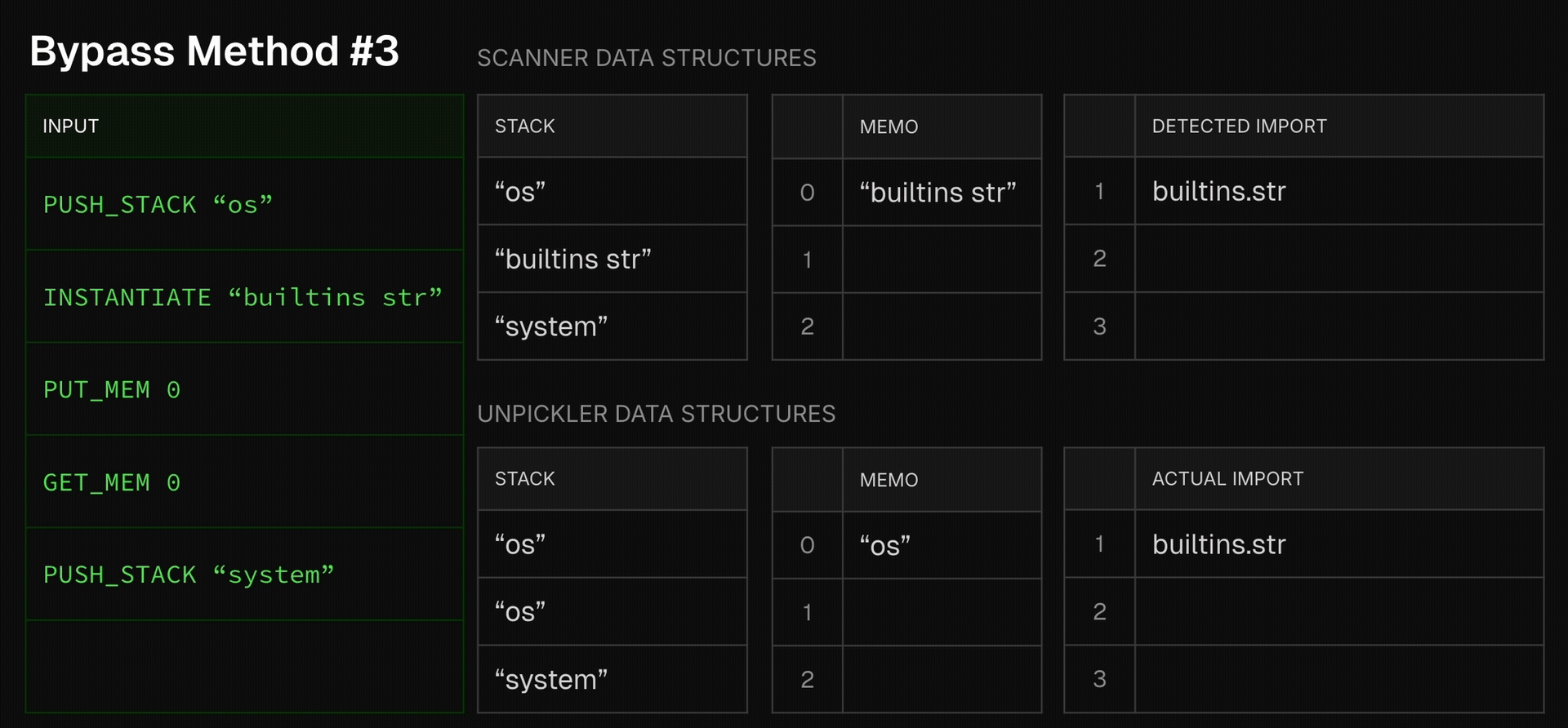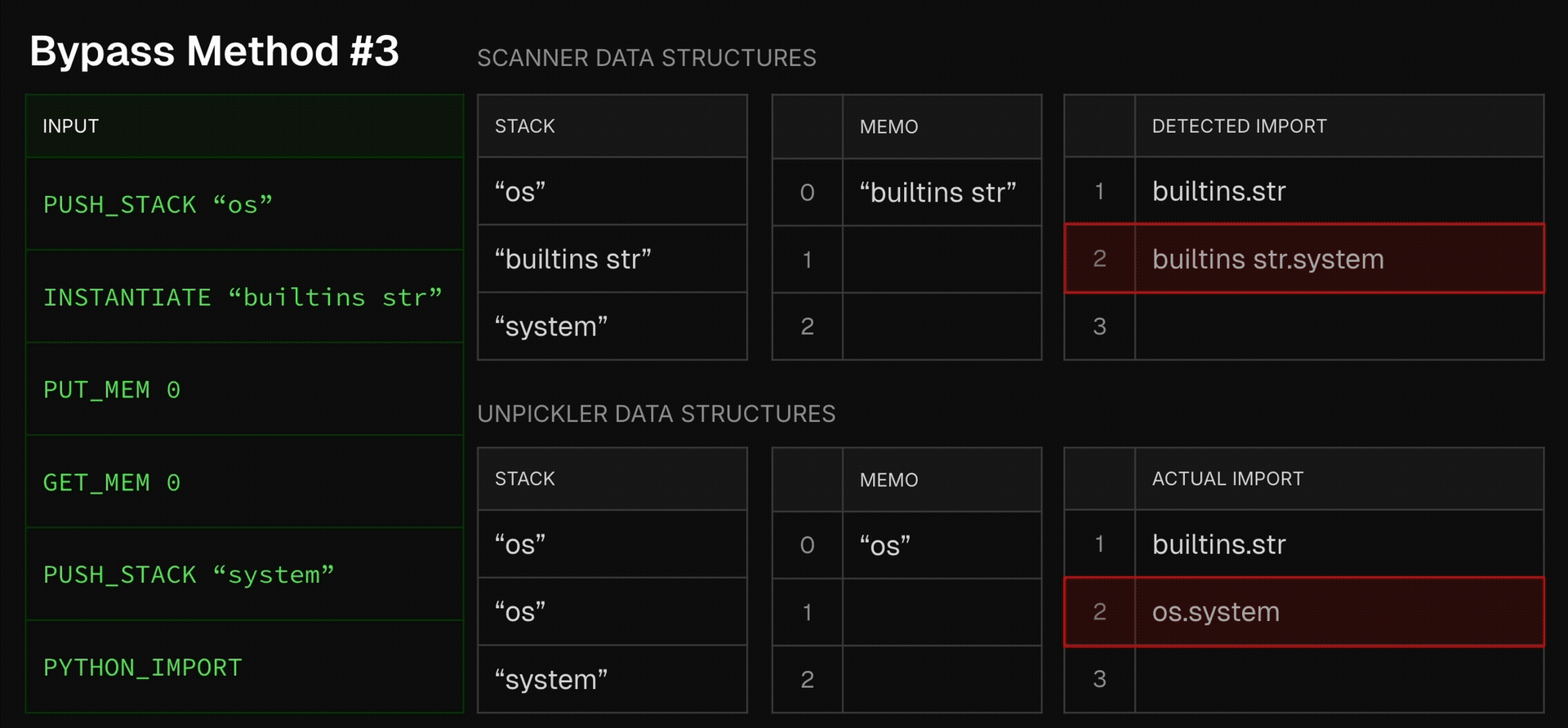
As we see here, by using the INSTANTIATE opcode, an attacker can take advantage of picklescan’s over-simplification, making it believe the INSTANTIATE’s argument was put in memory, when in fact its result was put into memory. This completely shakes the scanner’s ability to follow imports, as now the actual imported function differs from what the scanner thinks gets imported, and seeing that picklescan is based on a denylist, the scanner gets a denylist miss, and so concludes the file is not unsafe.
Bypass Method #4 - Using Complex Model Formats
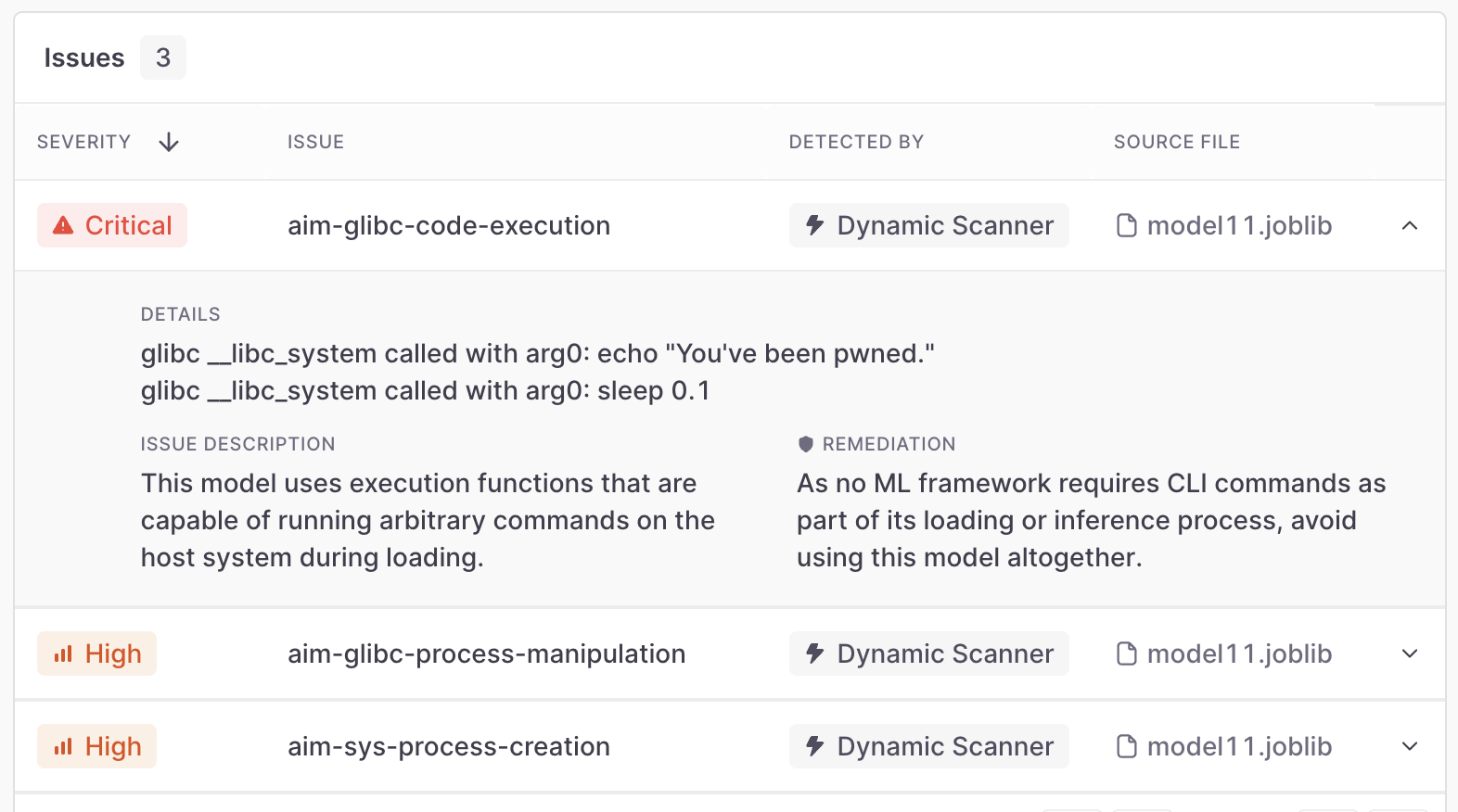
Another bypass method involves using complicated model serialization formats. One of those formats is Joblib, known for its optimization of numpy array storage and loading. As many classic ML frameworks, such as sklearn, rely at their core on numpy arrays, this format is commonly used by data scientists. In terms of its serialization, Joblib is very similar to pickle, with a slight, yet important, deviation- numpy array data is embedded in the middle of the pickle opcodes. Thus, a Joblib file is not a sequence of pickle opcodes which can be sequentially analyzed. Instead, it is a pickle blob that randomly becomes array bytes, then continues in the original pickle blob. It can then, of course, become again array bytes, and so on. To make things even worse, as numpy arrays might also be an array of objects, every now and then the interrupting array bytes might actually become other pickle blobs, which don’t share the same memory and stack as the original pickle blob. In short, a dynamically-determined chaos. Seeing that static scanners rely, well, on static analysis, static scanners normally stop parsing the Joblib file once they encounter the first non-pickle opcode. This allows attackers to easily embed malicious pickles after a random numpy array disrupts the static scanner’s emulation process. To visualize this:
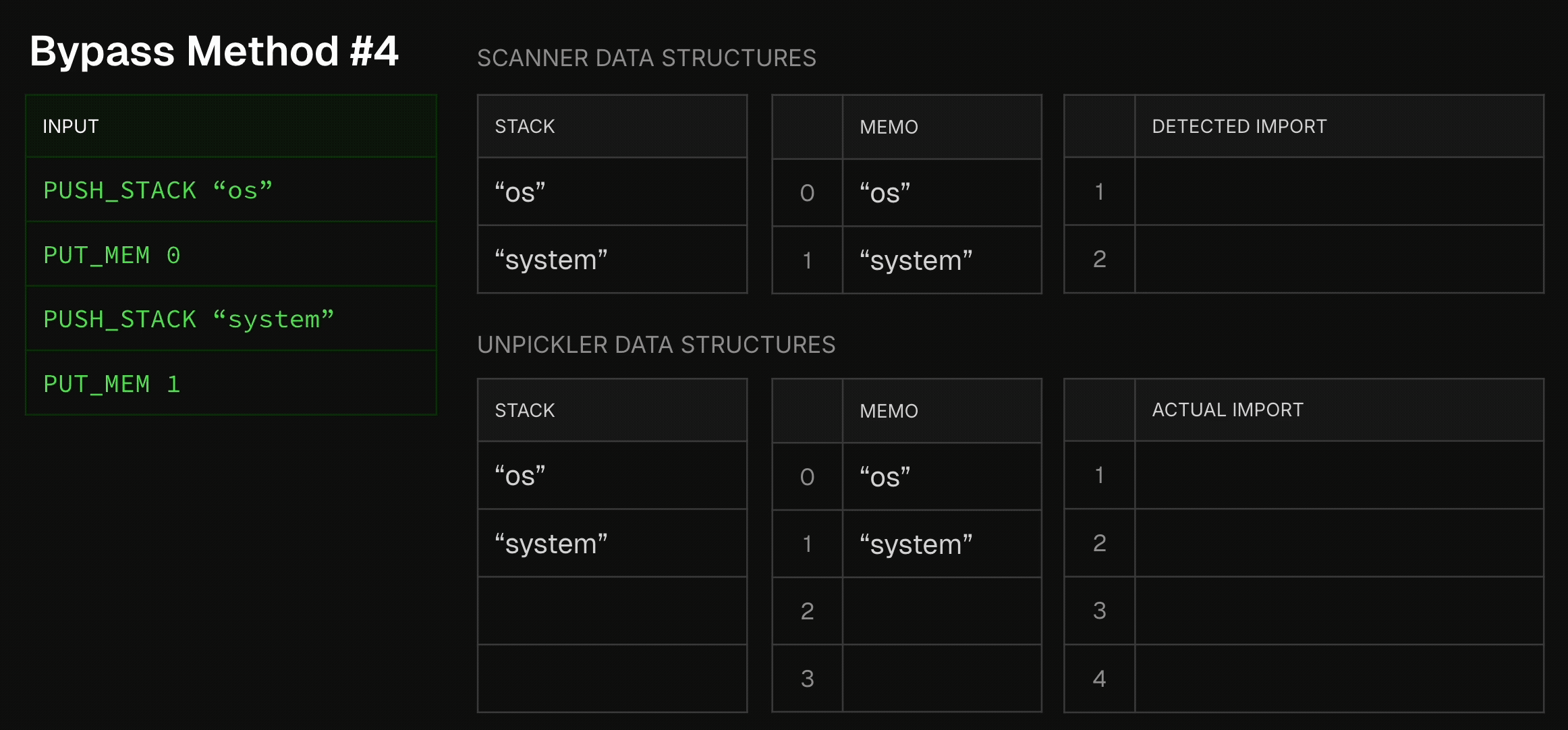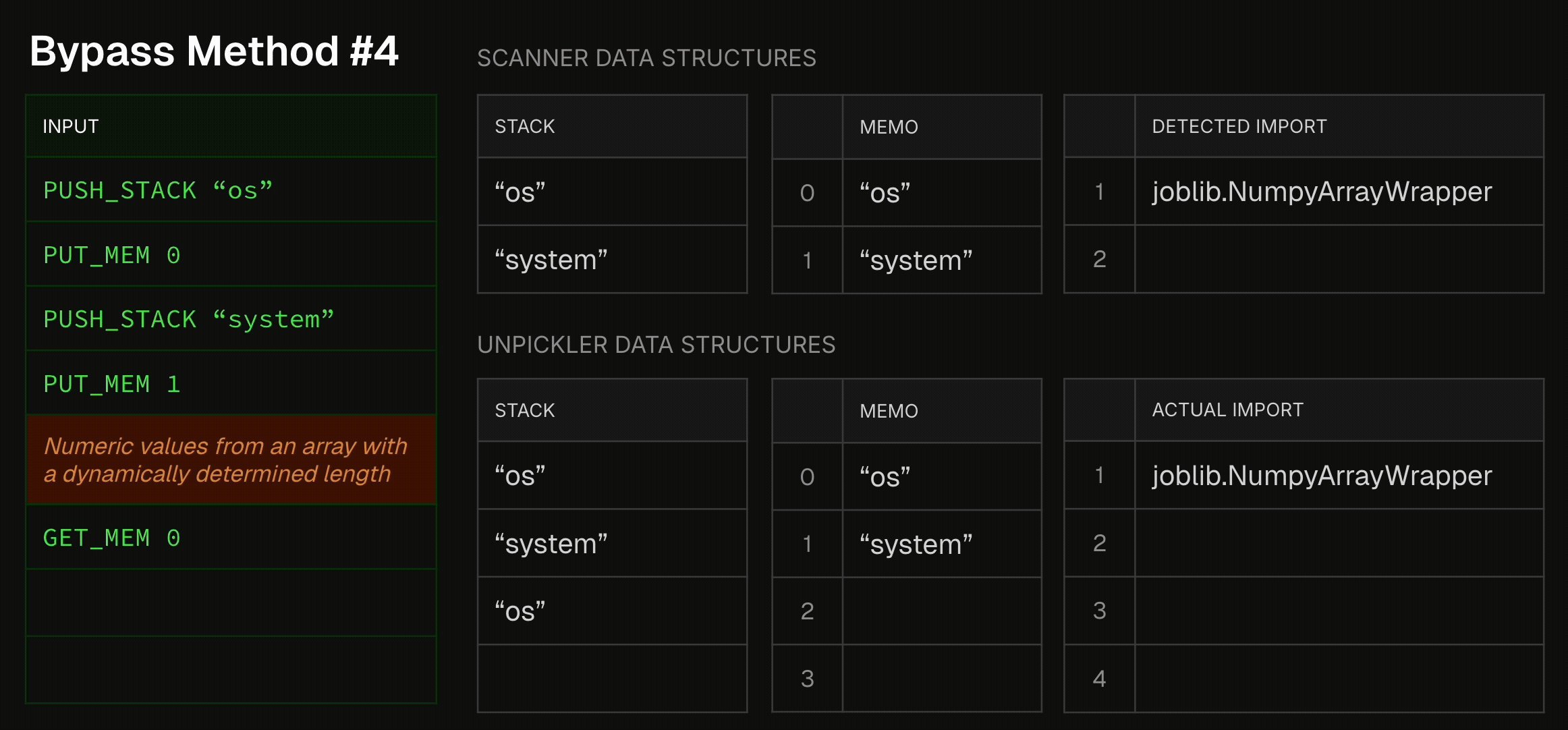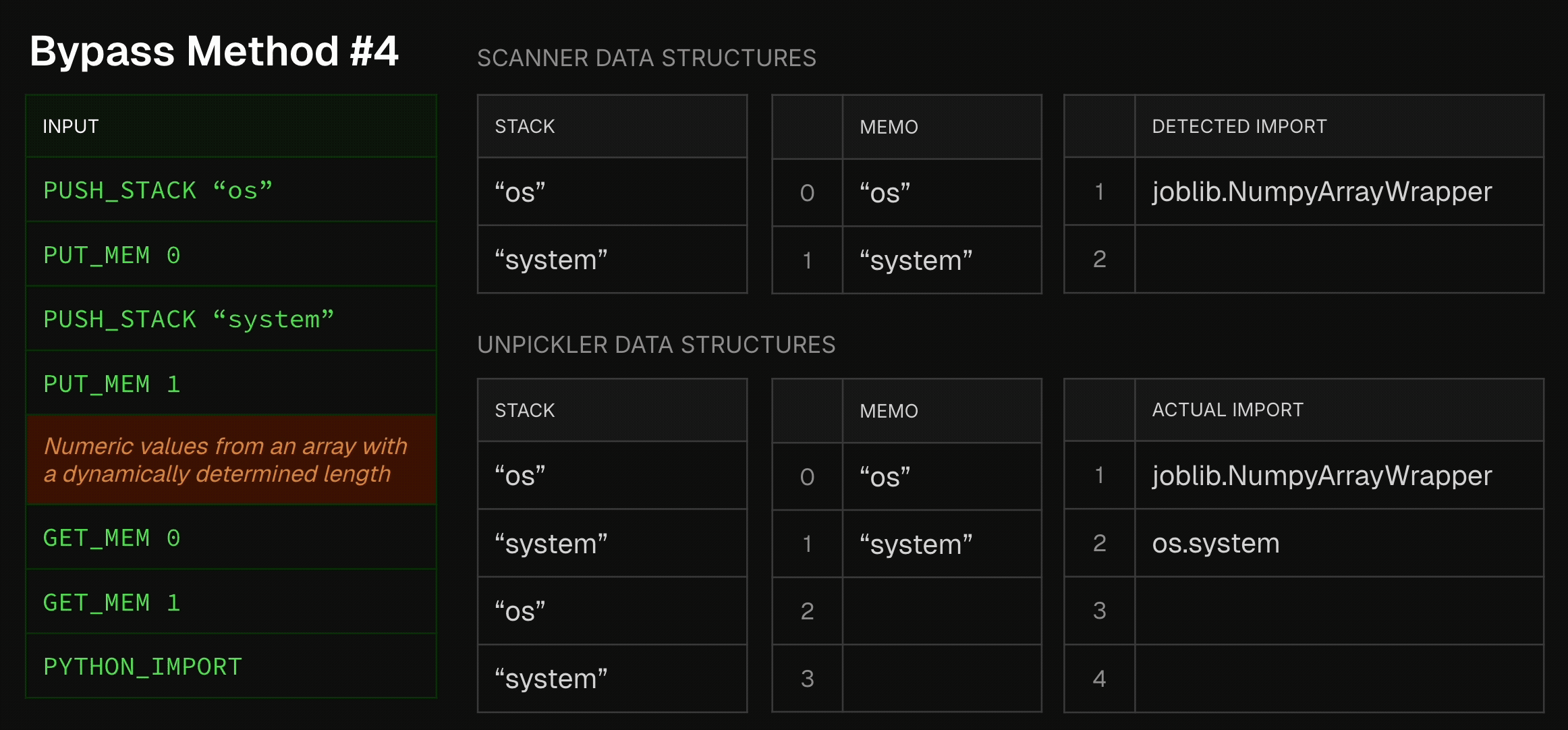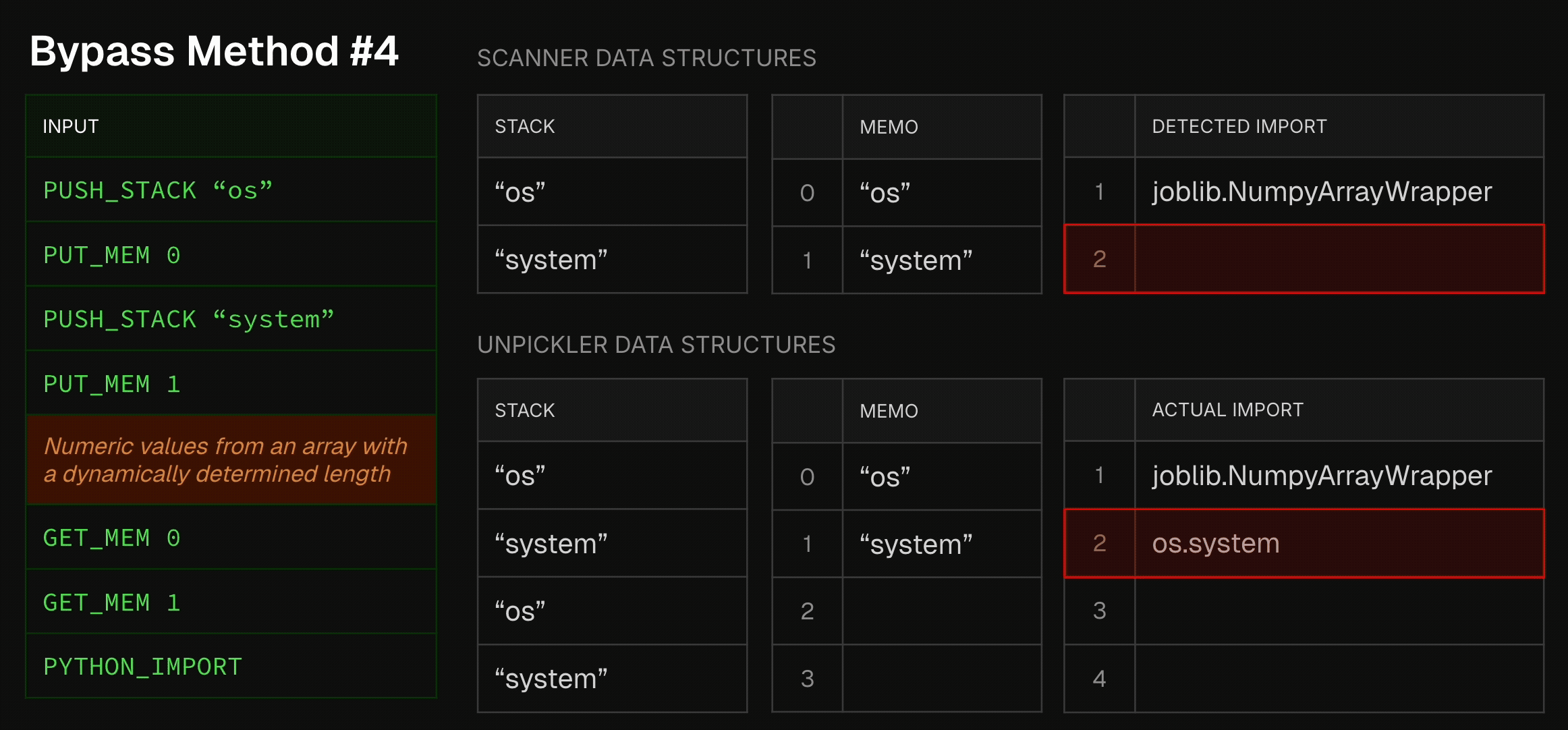
Allowlist-Based Scanners
Unfortunately, allowlist based scanners also can’t provide a true sense of security.
Many strong models do not conform to a “normal” allowlist. For example let’s consider the YOLO models family, from Ultralytics, a family of models that achieved state-of-the-art performance on multiple vision-related tasks. Not only that those models rely on a very non-standard pickle-import of a package named ultralytics, some of the models actually rely on pickle-importing the __builtin__.getattr function, which in other cases can be used to execute supply chain attacks on its own. This makes it impossible to add the pickle imports of the YOLO models to an allowlist.
Unfortunately, pickle is not the only source of concern for allowlist-based scanners. As many strong AI ideas start as custom architectures, most ML frameworks provide a method of loading custom architectures even when those do not rely solely on allowlisted functions. In HuggingFace’s transformers library, for example, which is capable of loading the unsafe SafeTensors format, a model can configure a special feature called “auto_map”. This tells the model loader that the source code for loading the model does not come from the transformers library itself, but rather from the model repository, again opening users to supply chain attacks. This time, static scanners don’t even try to make it seem as if those python files are scanned, because as we already mentioned, static code analysis is NP-hard. We can see one example for usage of this feature with the popular Chinese models DeepSeek-R1 and Kimi-K2:
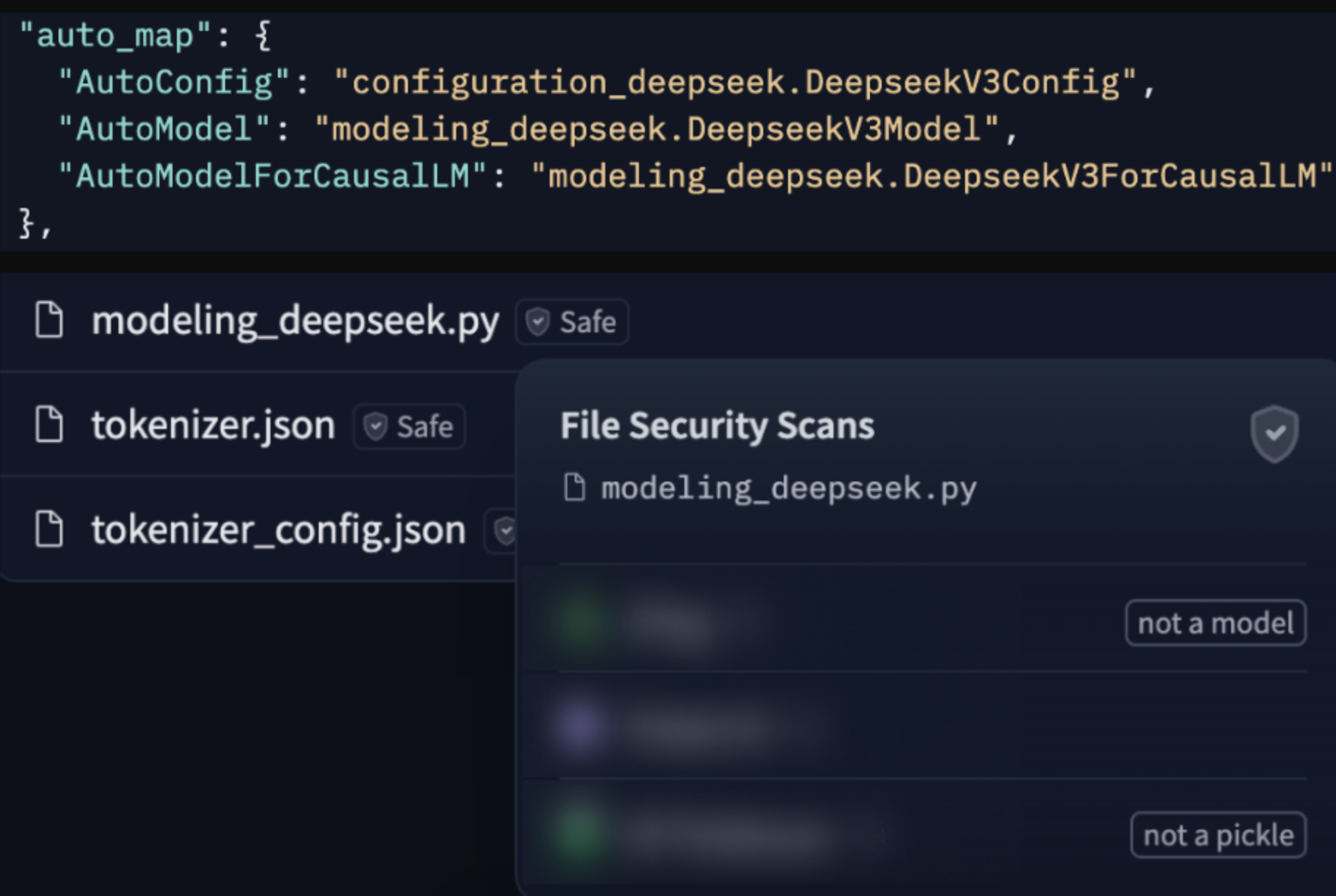
Although using such a feature requires the user to explicitly state they “trust_remote_code”, unfortunately users are not sufficiently equipped with tools to decide whether source code is worthy of their trust or not. Static scanners, sadly, currently provide no insights into source code files. Possibly though, this is preferable to a void attempt of statically analyzing source code providing a false sense of security, as it is doomed to be bypassed.
Worry Not, Next-Gen Scanners Are Already Here
To bridge these gaps, Aim Labs has devised a novel, patent-pending model scanning approach. This approach was inspired by the development process of classical malware detection. As static scanners essentially include static signatures on already-known malicious behaviors, much like Anti-Viruses in their early days, we were inspired by how far Anti-Viruses have come. Nowadays, EDRs heavily rely on executing suspicious executables in a sandbox environment, to trace the actual operations taken by this program.
Similarly, our approach utilizes tracing in a sandbox to inspect the actual operations taken by model loading and inference. There are many pros to using this approach:
- As this targets the “exploit” part of the supply-chain attack, rather than the bypass technique, it is capable of detecting 0-day attacks, as each attack needs some exploit to achieve its goal.
- As models essentially just read the model file from disk, it is very easy to construct an exhaustive set of “abnormal” operations for model loading and inference.
- Instead of statically analyzing complicated python bytecode, we simply run and trace it, to see what actually happens in practice.
- Regardless of the serialization’s nuances, all model formats have a very easy-to-use API. This makes loading and calling even the most convoluted formats such as Joblib a very easy task.
Simply tracing the model operations provides better insight into the model files. For example, if we consider the previous non-analyzable Joblib file, a dynamic scanner has no trouble detecting the malicious operation:
The mlflow-not-in-denylist example is also nearly trivial for a dynamic scanner, as it only looks for malicious operations in the trace, without following each function called in the process:
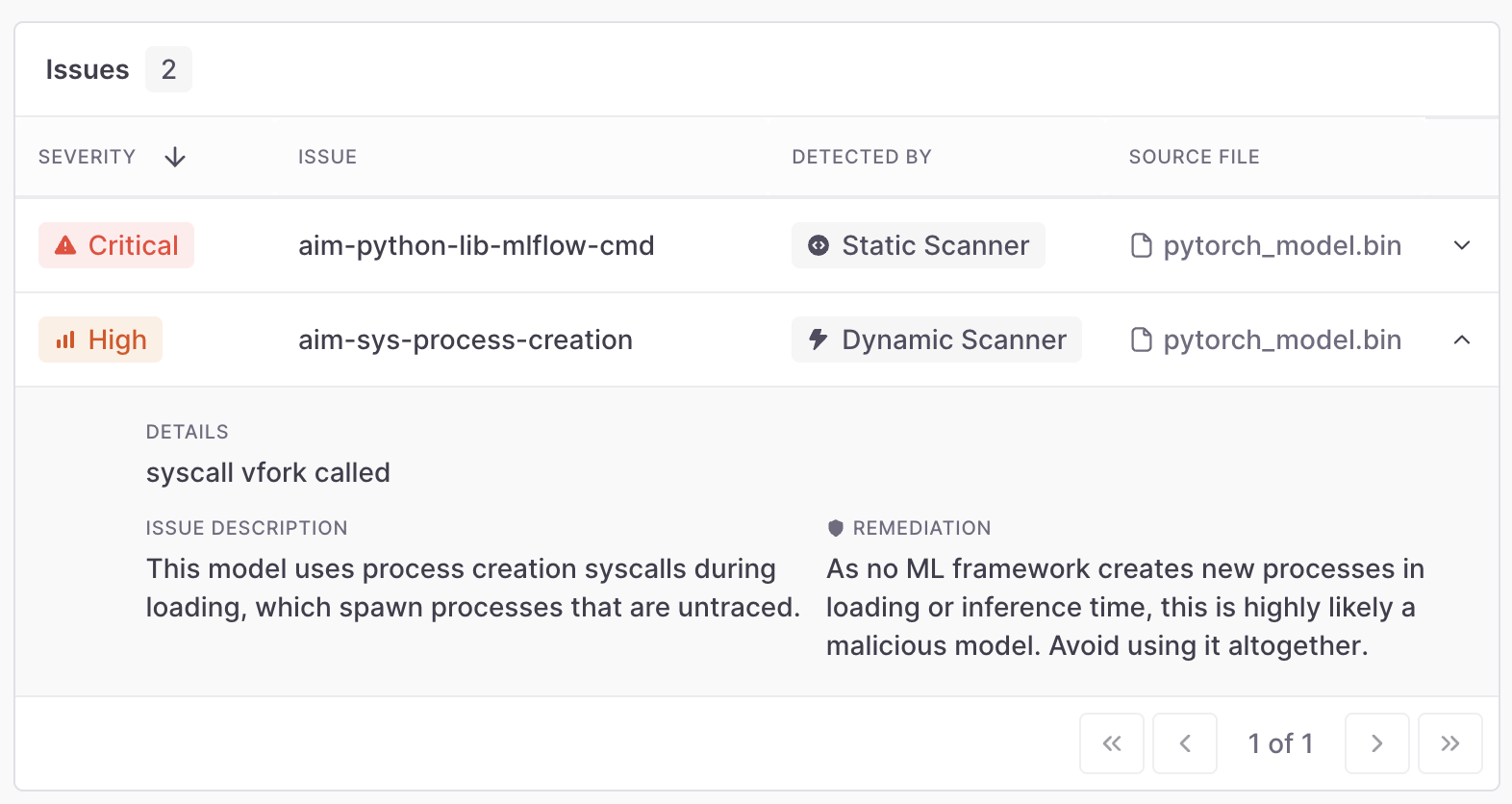
And of course, once we detected this novel mlflow method attackers use for supply chain attacks, we can update our static scanner accordingly:
Another interesting example we encountered involves a model trying to perform some operations over the network:
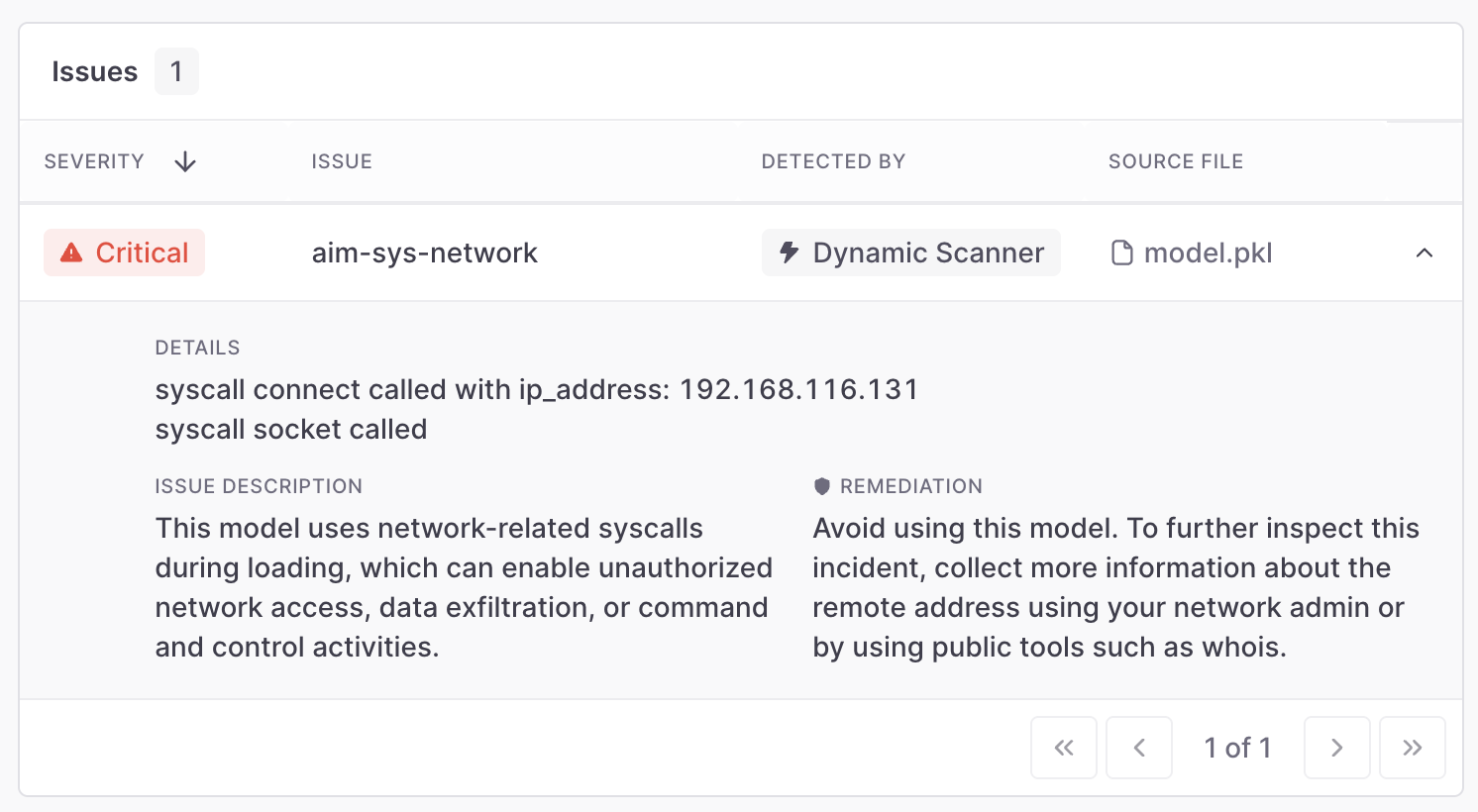
Lastly, we wanted to highlight the fact that this dynamic approach provides deep insight into the model file, in cases where the static scanner is limited. In the following example, all the static scanner manages to detect is the existence of a Keras Lambda function, which might be safe or not. It is unable to inspect the function’s bytecode to provide a better explanation as to whether this is safe, because of static code analysis’ complexity. In conjunction with the dynamic scanner, however, security teams can actually see deeper and understand that this is a malicious Lambda function, as it attempts to run CLI commands:
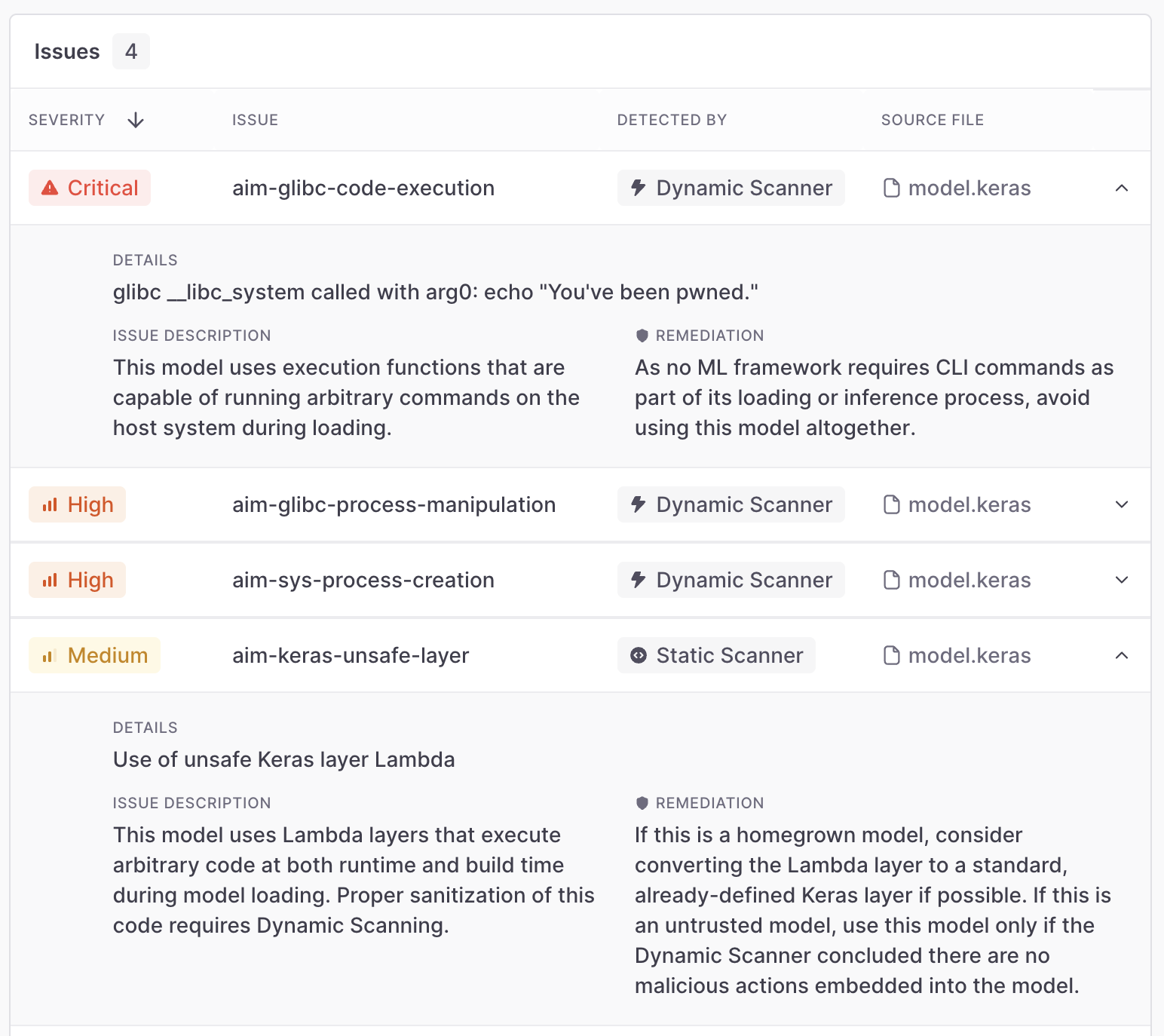
Closing Thoughts
Supply chain attacks by embedding malicious payloads into model files are an increasingly initial access vector for attackers. As data scientists experiment with third-party models found online on a daily basis, attackers are faced with multiple opportunities to inject their payloads into organizations.
Current protections are still lacking unfortunately. Even though we’ve only deep-dived into a few methods, we know of a dozen more that are not presented in this blogpost, to support our readers’ mental wellness.
Aim Labs’ dynamic approach to model scanning overcomes current scanners’ shortcomings, and provides deeper insight into what’s actually embedded into a model file. It is capable of detecting not-yet-seen attacks, providing insights into architectures that include code or bytecode, and is much more resilient than its static counterpart when it comes to relying on a preset denylist.
If you made it this far, kudos.
Feel free to reach out to labs@aim.security


